Microservices and Docker with .Net Core and Azure Service Fabric - Part two
I recently made some refactor/enhancements, take a look at the ChangeLog to view the details. TL;DR: upgrades to .Net Core 3.1, Kubernetes support, add a new notifications service, Health checks implementation.
In the previous post, we talked about what Microservices are, its basis, its advantages, and its challenges, also we talked about how Domain Driven Design (DDD) and Command and Query Responsibility Segregation (CQRS) come into play in a microservices architecture, and finally we proposed a handy problem to develop and deploy across these series of posts, where we analyzed the domain problem, we identified the bounded contexts and finally we made a pretty simple abstraction in a classes model. Now it’s time to talk about even more exciting things, today we’re going to propose the architecture to solve the problem, exploring and choosing some technologies, patterns and more, to implement our architecture using .Net Core, Docker and Azure Service Fabric mainly.
I would like starting to explain the architecture focused on development environment first, so I’m going to explain why it could be a good idea having different approaches to different environments (development and production mainly), at least in the way services and dependencies are deployed and how the resources are consumed, because, in the end, the architecture is the same both to development and to production, but you will notice a few slight yet very important differences.
Development Environment Architecture
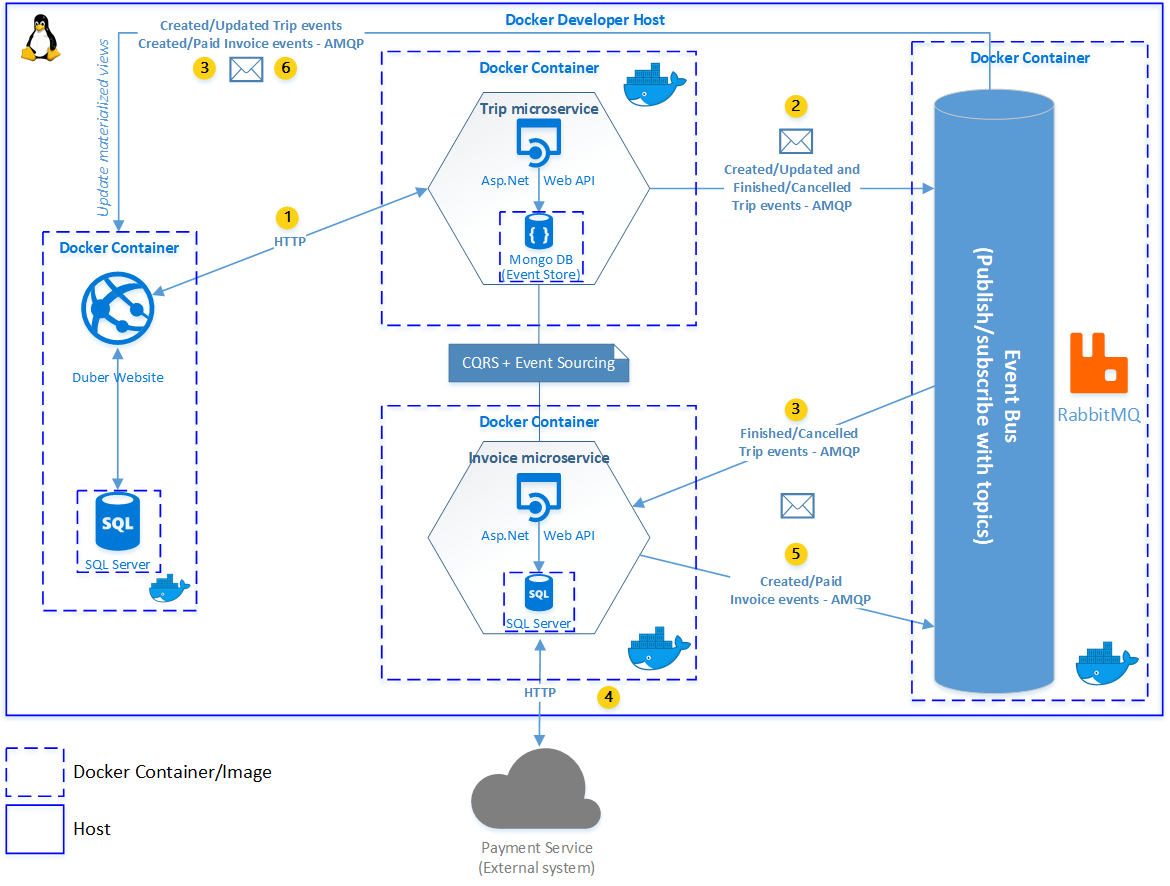
After you see the above image, you can notice at least one important and interesting thing: all of the components of the system (except the external service, obviously) are contained into one single host (later we’re going to explain why), in this case, the developer’s one (which is also a Linux host, by the way).
We’re going to start describing in a basic way the system components (later we’ll detail each of them) and how every component interacts to each other.
- Duber website: it’s an Asp.Net Core Mvc application and implements the User and Driver bounded context, it means, users and drivers management, service request, user and driver’s trips, etc.
- Duber website database: it’s a SQL Server database and is going to manage user, driver, trip and invoice data (last two tables are going to be a denormalized views to implement the query side of CQRS pattern).
- Trip API: it’s an Asp.Net Core Web API application, receives all services request from Duber Website and implements everything related with the trip (Trip bounded context), such as trip creation, trip tracking, etc.
- Trip API database: it’s a MongoDB database and will be the Event Store of our Trip Microservice in order to implement the Event Sourcing pattern.
- Invoice API: it’s an Asp.Net Core Web API application and takes care of creating the invoice and calling the external system to make the payment (Invoicing bounded context).
- Invoice API database: it’s a SQL Server database and is going to manage the invoice data.
- Payment service: it’s just a fake service in order to simulate a payment service.
Why Docker?
I would like starting to talk about Docker, in order to understand why is a key piece of this architecture. First of all, in order to understand how Docker works we need to understand a couple of terms first, such as Container image and Container.
- Container image: A package with all the dependencies and information needed to create a container. An image includes all the dependencies (such as frameworks) plus deployment and execution configuration to be used by a container runtime. Usually, an image derives from multiple base images that are layers stacked on top of each other to form the container’s filesystem. An image is immutable once it has been created.
- Container: An instance of a Container image. A container represents the execution of a single application, process, or service. It consists of the contents of a Docker image, an execution environment, and a standard set of instructions. When scaling a service, you create multiple instances of a container from the same image. Or a batch job can create multiple containers from the same image, passing different parameters to each instance.
Having said that, we can understand why one of the biggest benefits to use Docker is isolation, because an image makes the environment (dependencies) the same across different deployments (Dev, QA, staging, production, etc.). This means that you can debug it on your machine and then deploy it to another machine with the same environment guaranteed. So, when using Docker, you will not hear developers saying, “It works on my machine, why not in production?” because the packaged Docker application can be executed on any supported Docker environment, and it will run the way it was intended to on all deployment targets, and in the end Docker simplifies the deployment process eliminating deployment issues caused by missing dependencies when you move between environments.
Another benefit of Docker is scalability. You can scale out quickly by creating new containers, due to a container image instance represents a single process. Docker helps for reliability as well, for example with the help of an orchestrator (you can do it manually if you don’t have any orchestrator) if you have five instances and one fails, the orchestrator will create another container instance to replicate the failed process.
Another benefit that I want to note is that Docker Containers are faster compared with Virtual Machines as they share the OS kernel with other containers, so they require far fewer resources because they do not need a full OS, thus they are easy to deploy and they start fast.
Now that we understand a little bit about Docker (or at least the key benefits that it gives us to solve our problem), we can understand our Development Environment Architecture, so, we have six Docker images, (the one for SQL Server is the same for both Invoice Microservice and Duber Website), one image for Duber Website, one for SQL Server, one for Trip Microservice, one for MongoDB, one for Invoice Microservice and one image for RabbitMQ, all of them running inside the developer host (in the next post we’re going to see how Docker Compose and Visual Studio 2017 help us doing that). So, why that amount of Docker images, what is the advantage to use them in a development environment? well, think about this: have you ever have struggled trying to set up your development environment, have you lost hours or even days doing that? (I did! it’s awful), well, for me, there are at least two great advantages with this approach (apart from isolation), the first one is that it helps to avoid developers to waste time setting up the local environment, thus it speeds up the onboarding time for a new developer in the team, so, this way you only need cloning the repository and press F5, and that’s it! you don’t have to install anything on your machine or configure connections or something like that (the only thing you need to install is Docker CE for Windows), that’s awesome, I love it!
Another big advantage of this approach is saving resources. This way you don’t need to consume resources for development environment because all of them are in the developer’s machine (in a green-field scenario). So, in the end, you’re saving important resources, for instance, in Azure or in your own servers. Of course, you’re going to need a good machine for developers so they can have a good experience working locally, but in the end, we always need a good one!
As I said earlier, all of these images are Linux based on, so, how’s this magic happening in a Windows host? well, Docker image containers run natively on Linux and Windows, Windows images run only on Windows hosts and Linux images run only on Linux hosts. So, Docker for Windows uses Hyper-V to run a Linux VM which is the “by default” Docker host. I’m assuming you’re working on a Windows machine, but if not, you can develop on Linux or macOS as well, for Mac, you must install Docker for Mac, for Linux you don’t need to install anything, so, in the end, the development computer runs a Docker host where Docker images are deployed, including the app and its dependencies. On Linux or macOS, you use a Docker host that is Linux based and can create images only for Linux containers.
Docker is not mandatory to implement microservices, it’s just an approach, actually, microservices does not require the use of any specific technology!
Why .Net Core?
Is well known that .Net Core is cross-platform and also it has a modular and lightweight architecture that makes it perfect for containers and fits better with microservices philosophy, so I think you should consider .Net Core as the default choice when you’re going to create a new application based on microservices.
So, thanks to .Net Core’s modularity, when you create a Docker image, is far smaller than a one created with .Net Framework, so, when you deploy and start it, is significative faster due to .Net Framework image is based on Windows Server Core image, which is a lot heavier that Windows Nano Server or Linux images that you use for .Net Core. So, that’s a great benefit because when we’re working with Docker and microservices we need to start containers fast and want a small footprint per container to achieve better density or more containers per hardware unit in order to lower our costs.
Additionally, .NET Core is cross-platform, so you can deploy server apps with Linux or Windows container images. However, if you are using the traditional .NET Framework, you can only deploy images based on Windows Server Core.
Also, Visual Studio 2017 has a great support to work with Docker, you can take a look at this.
Production Environment Architecture
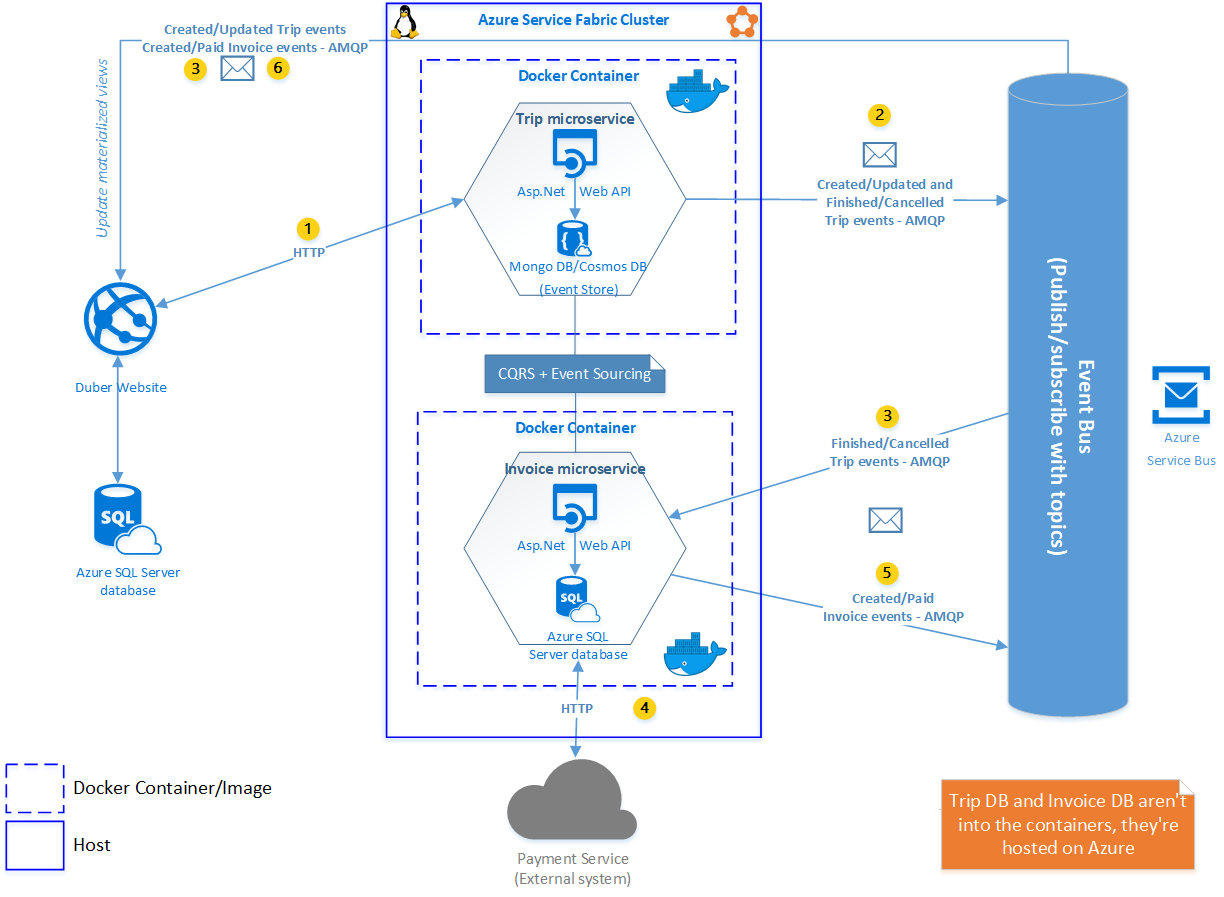
Before talking about why we’re going to use Azure Service Fabric as an orchestrator I would like to start explaining the Production Environment Architecture and its differences respect to the Development one. So, there are three important differences, one of them, as you can notice, in this environment we have only two Docker images instead of six, which are for Trip and Invoice microservices, that, in the end, they’re just a couple of API’s, but why two instead of six? well, here is the second important difference, in a production environment we don’t want that our resources, such as databases and event bus are isolated into an image and even worst dispersed around the nodes among the clusters (we’re going to explain these terms later) as silos. We need to be able to scale out these resources as needed, that’s why we’re going to use Microsoft Azure to host those resources, in this case, we’re going to use Azure SQL Databases for Duber website and Invoice microservice. For our Event Store, we’re going to use MongoDB over Azure Cosmos DB which give us great benefits. Lastly instead of RabbitMQ we’re going to use the Azure Service Bus. So, in the production environment our Docker containers are going to consume external resources like the databases and the event bus instead of using those resources inside the container host as a silo.
Speaking about a little bit why we have a message broker, basically, it’s because we need to keep our microservices decouple to each other, we need the communication between them to be asynchronous so to not affect the performance, and we do need to guarantee that all messages will be delivered. In fact, a message broker like Azure Service Bus helps us to solve one of the challenges that microservices brings to the table: communication, and also enforces microservices autonomy and give us better resiliency, so using a message broker, at the end of the day, it means that we’re choosing a communication protocol called AMQP, which is asynchronous, secure, and reliable. Whether or not you use a message broker you have to pay special attention to the way that microservices communicates to each other, for example, if you’re using an HTTP-based approach, that’s fine for request and responses just to interact with your microservices from client applications or from API Gateways, but if you create long chains of synchronous HTTP calls across microservices you will eventually run into problems such as blocking and low performance, coupling microservices with HTTP and resiliency issues, when any of the microservices fails the whole chain of microservices will fail. It is recommended to avoid synchronous communication and ONLY (if must) use it for internal microservices communication, but, as I said, if there is not another way.
I have chosen Azure Service Bus instead of RabbitMQ for production environment just to show you that in development environment you can use a message broker on-premise (even though Azure Service Bus works on-premise as well) and also because I’m more familiarized with Azure Service Bus and I think it’s more robust than RabbitMQ, but you can work with RabbitMQ in production environments as well if you want it, it’s a great product.
Another thing that I want to note is that Duber Website is not inside a docker container and it’s not deployed like a microservice, because usually a website doesn’t require processing data or has business logic, sometimes, having a few instances to manage them with a Load Balancer is enough, so that’s why doesn’t make sense treat the frontend as a microservice, even though you can deploy it as a Docker container, that’s useful, but in this case, it just will be an Azure Web Site.
Orchestrators and why Azure Service Fabric?
One of the biggest challenges that you need to deal with when you’re working with a microservice-based application is complexity. Of course, if you have just a couple of microservices probably it won’t be a big deal, but with dozens or hundreds of types and thousands of instances of microservices it could be a very complex problem, for sure. It’s not just about building your microservice architecture, you need to manage the resources efficiently, you also need high availability, addressability, resiliency, health, and diagnostics if you intend to have a stable and cohesive system, that’s why we’re going to need an orchestrator to tackle those problems.
The idea of using an orchestrator is to get rid of those infrastructure challenges and focus only on solving business problems, if we can do that, we will have a worthwhile microservice architecture. There are a few microservice-oriented platforms that help us to reduce and deal with this complexity, so we’re going to take a look at them and pick one, in this case, Azure Service Fabric will be the chosen one, but before that, we’re going to explain a couple of terms that I introduced you earlier, such as Clusters and Nodes, because I think they are the building block of orchestrators due to they enable concepts like high availability, addressability, resiliency, etc. so it’s important to have them clear. By the way, they are pretty simple to understand.
- Node: could be a virtual or physical machine which lives inside of a cluster.
- Cluster: a cluster is a set of nodes that can scale to thousands of nodes (Cluster can be scale out as well).
So, we’re going to explain briefly the most important orchestrators that exist currently in order to be aware of the options that we have when we’re working with microservices.
- Kubernetes: is an open-source product originally designed by Google and now maintained by the Cloud Native Computing Foundation that provides functionality that ranges from cluster infrastructure and container scheduling to orchestrating capabilities. It lets you automate deployment, scaling, and operations of application containers across clusters of hosts. Kubernetes provides a container-centric infrastructure that groups application containers into logical units for easy management and discovery. Kubernetes is mature in Linux, less mature in Windows.
- Docker Swarm: Docker Swarm lets you cluster and schedule Docker containers. By using Swarm, you can turn a pool of Docker hosts into a single, virtual Docker host. Clients can make API requests to Swarm the same way they do to hosts, meaning that Swarm makes it easy for applications to scale to multiple hosts. Docker Swarm is a product from Docker, the company. Docker v1.12 or later can run native and built-in Swarm Mode.
- Mesosphere DC/OS: Mesosphere Enterprise DC/OS (based on Apache Mesos) is a production-ready platform for running containers and distributed applications. DC/OS works by abstracting a collection of the resources available in the cluster and making those resources available to components built on top of it. Marathon is usually used as a scheduler integrated with DC/OS. DC/OS is mature in Linux, less mature in Windows.
- Azure Service Fabric: It is an orchestrator of services and creates clusters of machines. Service Fabric can deploy services as containers or as plain processes. It can even mix services in processes with services in containers within the same application and cluster. Service Fabric provides additional and optional prescriptive Service Fabric programming models like stateful services and Reliable Actors. Service Fabric is mature in Windows (years evolving in Windows), less mature in Linux. Both Linux and Windows containers are supported in Service Fabric since 2017.
Microsoft Azure offers another solution called Azure Container Service which is simply the infrastructure provided by Azure in order to deploy DC/OS, Kubernetes or Docker Swarm, but ACS does not implement any additional orchestrator. Therefore, ACS is not an orchestrator as such, only an infrastructure that leverages existing open-source orchestrators for containers that enables you to optimize the configuration and deployment, for instance, you can select the size, the number of hosts, and the orchestrator tools, and Container Service handles everything else.
So, we’re going to use Azure Service Fabric to deploy our microservices because it provides us a great way to solve hard problems such as deploying, running, scale out and utilizing infrastructure resources efficiently due to Azure Service Fabric enables you to:
- Deploy and orchestrate Windows and Linux containers.
- Deploy applications in seconds, at high density with hundreds or thousands of applications or containers per machine.
- Deploy different versions of the same application side by side, and upgrade each application independently.
- Manage the lifecycle of your applications without any downtime, including breaking and nonbreaking upgrades.
- Scale out or scale in the number of nodes in a cluster. As you scale nodes, your applications automatically scale.
- Monitor and diagnose the health of your applications and set policies for performing automatic repairs.
- Service Fabric recovers from failures and optimizes the distribution of load based on available resources.
If you don’t have a Microsoft Azure account, you can get it joining to Visual Studio Dev Essentials program, which gives to developers a valuable resources and tools for free. By the way, just a little advice, manage those resources wisely!
Service Fabric powers many Microsoft services today, including Azure SQL Database, Azure Cosmos DB, Cortana, Microsoft Power BI, Microsoft Intune, Azure Event Hubs, Azure IoT Hub, Dynamics 365, Skype for Business, and many core Azure services.
CQRS and Event Sourcing
As I said in the previous post, we’re going to use CQRS in order to resolve the challenge to get computed data through our microservices, since we can’t just do a query joining tables in different kind of stores, also we will do it thinking that it allow us to scale the read side and write side of the application independently (I love this benefit). So, we’re going to use the command model to process all the requests from Duber Website, that means, the command-side will take care of to create and update the trip. The most important point here is that we’re going to take advantage of CQRS by splitting the read and the command sides, in our case we’re going to implement the read-side just hydrating a materialized view that lives into Duber Website’s database with the trip and invoice information that comes from trip and invoice microservices respectively through our Event Bus that keeps up to date the materialized view by subscribing it to the stream of events emitted when data changes. So, that way we’re going to retrieve the data easily from a denormalized view from a transactional database. By the way, I want to note that we won’t use a service bus (that’s not mandatory) to transport the commands from Duber Website due to the Trip microservice will be consumed via HTTP as I explained earlier, in order to simplify the problem and given the fact that we don’t have an API Gateway in our architecture, the important thing is to implement the command handlers and the dispatcher that is in charge to dispatch the command to an aggregate.
Speaking about Event Sourcing, it will help us to solve our problem about tracking the trip information since event sourcing is the source of truth due to it persists the state of a business entity (such as Trip) as a sequence of state-changing events at a given point of time. So, whenever the state of a business entity changes, the system saves this event in an event store. Since saving an event is a single operation, it is inherently atomic. Thus, the event store becomes the book of record for the data stored by the system, providing us a 100% reliable audit log of the changes made to a business entity and allowing us go beyond, to audit data, gain new business insights from past data and replay events for debugging and problem analysis. In this case we’re going to use MongoDB as an Event Store, however, you can consider other alternatives such as Event Store, RavenDB, Cassandra, DocumentDB (which is now CosmosDB).
Well, we have dived deep in the architecture and evaluated different options, so, given that now we are aware of the upsides and downsides of our architecture and we have chosen the technologies conscientiously, we can move on and start implementing our microservice based system! so, stay tuned because in the next post we’re going to start coding! I hope you’re enjoying this topic as much as me and also hope it will be helpful!