Microservices and Docker with .Net Core and Azure Service Fabric - Part One
I recently made some refactor/enhancements, take a look at the ChangeLog to view the details. TL;DR: upgrades to .Net Core 3.1, Kubernetes support, add a new notifications service, Health checks implementation.
The first time I heard about Microservices I was impressed by the concept and even more impressed when I saw microservices in action, it was like love at first sight, but a complicated one, because it was a pretty complex topic (even now). By that time, I had spent some time studying DDD (Domain Driven Design), and for me, it was incredible that a book written in 2003 (more than the book the topic itself because Eric Evans created a new architectural style. A lot of people think DDD is an architectural pattern, but for me, it goes beyond a “pattern”, because DDD touches a lot of edges than just one specific problem) would have so much relevance, similarities and would fit so well (from the domain side) with a “modern” architecture such as Microservices. I know that the Microservices concept (or at least the core ideas) comes from many years ago when Carl Hewitt in the early 70’s started to talk about his Actors Model and even later when SOA architecture had solved a lot of problems in the distributed systems; even when a lot of people say “Microservices are basically SOA well done”. Maybe is right (I don’t think so), but the truth is that concepts such as redundant implementation (scale out), service registry, discoverability, orchestration and much more which are the building block of Microservices, come from SOA.
So, after that, I decided to study the fundamentals of Microservices in order to understand its origin and then I got a SOA Architecture certification (that’s not the important thing, it was the journey) and I managed to learn and understand how SOA architecture has helped along from these last years to “evolve” what today we know like Microservices (and finally understand why a bunch of people say “Microservices are basically SOA well done”). Later, after an SOA conscientious study, I learned a lot of things related with Microservices, but I put my eye especially on CQRS (I strongly recommend you read this book), which is an architectural pattern that, combined with Event Sourcing, are very useful and powerful tools when we’re going to work with Microservices.
So this time, I would like to show you in several posts how to build microservices using .Net Core and Docker applying DDD, CQRS and other architectural/design patterns, and finally how to use Azure Service Fabric to deploy our microservices. At the end, I just want to tell you what was my focus in the Microservices journey and how I started to dive into it and how I put that knowledge in practice, I just want to encourage you to jump into the microservices world and learn a lot of cool things related with this challenging yet awesome world.
The scope of these series of posts won’t explain how DDD and CQRS work, I’m just going to explain how they both can help within a Microservices architecture and how to implement them. On the other hand, I highly recommend you to read the Eric Evans and Vaughn Vernon’s books if you want to learn more about DDD and, the CQRS Journey book if you want to learn more about CQRS.
I’m going to start highlighting the most important benefits of working with microservices and on the other hand, the great challenges that bring this approach in order to be aware of when and why we can use it. Also, I’m going to explain how DDD and CQRS can help when we’re working with microservices and finally how Docker containers is a great option to isolate our microservices and how its isolation can help us a lot in a development environment and when we need to deploy in our production environments, in this case, with help of Azure Service Fabric as Orchestrator to manage our microservices. So, at the end of the day, I’ll walk you through an introduction to microservices with a practical example that we’re going to develop and deploy in these series of posts, Let’s get started!
What are Microservices?
In a nutshell, Microservices architecture is an approach to build small, autonomous, independent and resilient services running in its own process. Each service must implement a specific responsibility in the domain, it means a microservice can’t mix domain/business responsibilities, because it is autonomous and independent, so in the end, each microservice has its own database.
Benefits
Resiliency:
When a single microservice fails for whatever reason (service is down, the node was restarted/shut down or another temporal error), it won’t break the whole application, instead, another microservice could respond to that fail request and “do the work” for the instance with error. (It’s like when you have a friend that helps you when you’re in troubles) So, is important to implement techniques in order to enable resiliency and manage the unexpected failures, such as circuit-breaking, latency-aware, load balancing, service discovery, retries, etc. (Most of these techniques are already implemented by the orchestrators)
Scalability:
Each microservice can scale out independently, so, you don’t need to scale the whole system (unlike the monolithic applications), instead, you can scale out only the microservices that you need when you need. In the end, it allows you to save in costs because you’re going to need less hardware.
Data isolation:
Because every microservice has its own database is much easier to scale out the database or data layer, and changes related with a data structure or even data, have less impact because the changes only affect one part of the system (one microservice), making the database more maintainable and helping with the data governability. Also, it allows you to have a polyglot persistence system and choose a more suitable database depending on the needs of your microservice.
Small teams:
Because each microservice is small and has a single responsibility in terms of domain and business, every microservice could have a small team, since it doesn’t share the code nor database, so is easier to make a change or add a new feature because it doesn’t have dependencies whit other microservices or another component of the system. Additionally, and thanks to the small team, it promotes agility.
Mix of technologies:
Thanks to the fact that every single team is small and independent enough, we can have a rich microservices ecosystem because, for instance, you could have a team working with .Net Core for one microservice while another team works on NodeJS for a different microservice and it doesn’t matter because none of the microservices depend on each other.
Long-term agility:
Since microservices are autonomous, they are deployed independently, so that makes easier to manage the releases or bug fixes, unlike monolithic applications where any bug could block the whole release process while the team have to wait for the bug is fixed, integrated, tested and published, even though when the bug isn’t related to the new feature. So, you can update a service without redeploying the whole application or roll back an update if something goes wrong.
Challenges
Choosing right size:
When you design a microservice you need to think carefully about its purpose and responsibility in order to build a consistent and autonomous microservice, so it should not be too big nor too small. DDD is a great approach to design your microservices (it’s not mandatory nor a golden hammer, but in this case we’re going to use it to design our system) because DDD helps you to keep your domain decoupled and consistent, so if you already know something about DDD, you probably know that a Bounded Context is a great candidate to be a microservice. At the end, the key point is choosing the right service boundaries for your microservices, independently if you use DDD or not.
Complexity:
Unlike monolithic applications where you deal only with just one big piece of software, in a microservices architecture you have to deal with a bunch of pieces of software (services), so, while in a monolithic application one business operation (or business capability) could interact with one service (or even none) in a microservices architecture one business operation could interact with a lot of services, so you need to manage a lot of things, such as: communication between client and microservices, communication between microservices, coordination, handling errors, compensating transactions and so on. Also, microservices requires more effort in governability stuff, like continuous integration and delivery (CI/CD).
Queries:
Since every microservice has its own database you couldn’t simply make a query joining tables, because, for instance, you can´t access a customer information from the invoice microservice or even from the client, or even something more complicated, you could have different kinds of databases (SqlServer, MongoDB, ElasticSearch, etc) for every microservice. So, in this case, we’re going to use CQRS to figure it out.
Data consistency and integrity:
One of the biggest challenges in microservices is to keep the data consistent, because as you already know every microservice manage its own data. So, if you need to keep a transaction along multiples microservices you couldn’t use an ACID transaction because your data is distributed in several databases. So, one of the common and good solutions is to implement the Compensating Transaction pattern. On the other hand, other common approaches like distributed transactions are not a good idea in a microservices architecture because many modern (NoSQL) databases don’t support it, also it is a blocking protocol and commonly relies on third-party product vendors like Oracle, IBM, etc. Lastly one of the biggest considerations about distributed transactions is the CAP theorem that states that in a distributed data store is impossible to guarantee consistency and availability at the same time, so you need to choose one of them and pay off. In other words, the CAP theorem means if you’re using a blocking strategy like ACID or 2PC transactions you’re not being available (for the time the resources are blocking) even if you’re using compensating transactions you´re not being consistent because of the delay of the undo operations among the involved microservices, so in the end, as I said, you need to choose and pay off.
Communication:
As I said earlier since you have a lot of small services, the communication between the client and different microservices could be a headache and pretty complex task, so there are several and common solutions such as an API Gateway, service mesh or a reverse proxy.
Now that we know what microservices are, its advantages and challenges, I’m going to propose a handy problem and we’re going to see how a microservice architecture can help us. Then, we’re going to develop a solution based on these concepts, and at the end of these series of posts we should be able to see a microservices solution working and we will solve the problem proposed.
The problem
DUber is a public transport company that matches drivers with users that require a taxi service in order to move them from one place to another through an App that allows them to request a service using their current location and picking up the destination on a map. The main problems that DUber is facing at this time are:
- DUber became a pretty popular application and it’s used by millions of people, but currently, it has scaling problems due to its monolithic architecture.
- In the rush hours the DUber’s services collapse because the system can’t support the big amount of requests.
- DUber is facing problems tracking all about the trip, since it starts until it ends. So user and driver aren’t aware, for instance when a service is canceled or the driver is on the way, etc.
- Since the current architecture is a monolithic one and the team is very big, the release process in DUber takes long time, especially for bugs because before the fix is released, is necessary to test and redeploy the whole application.
- Sometimes the development team loses a lot of time setting the development environment up due to the dependencies and even in the QA and production environments there are errors like: “I don’t know why, but in my local machine works like a charm”
As you can see DUber is facing problems related to scalability, availability, agility and tracking business objects/workflows. So, we’re going to tackling those problems with a Microservice architecture helped by DDD, CQRS, Docker and Azure Service Fabric mainly, but first, we’re going to start analyzing the problem making a business domain model helped by DDD.
Business domain model
Here is when DDD comes into play to help us into an architecture based on Microservices. Before understanding the problem the first thing is understanding the business, the domain, so, after that, you will be able to make a domain model, which is a high-level overview of the system. It helps to organize the domain knowledge and provides a common language for developers and domain experts which Eric Evans called ubiquitous language. The main idea is mapping all of the business functions and their connections which is a task that involves domain experts, software architects and other stakeholders.
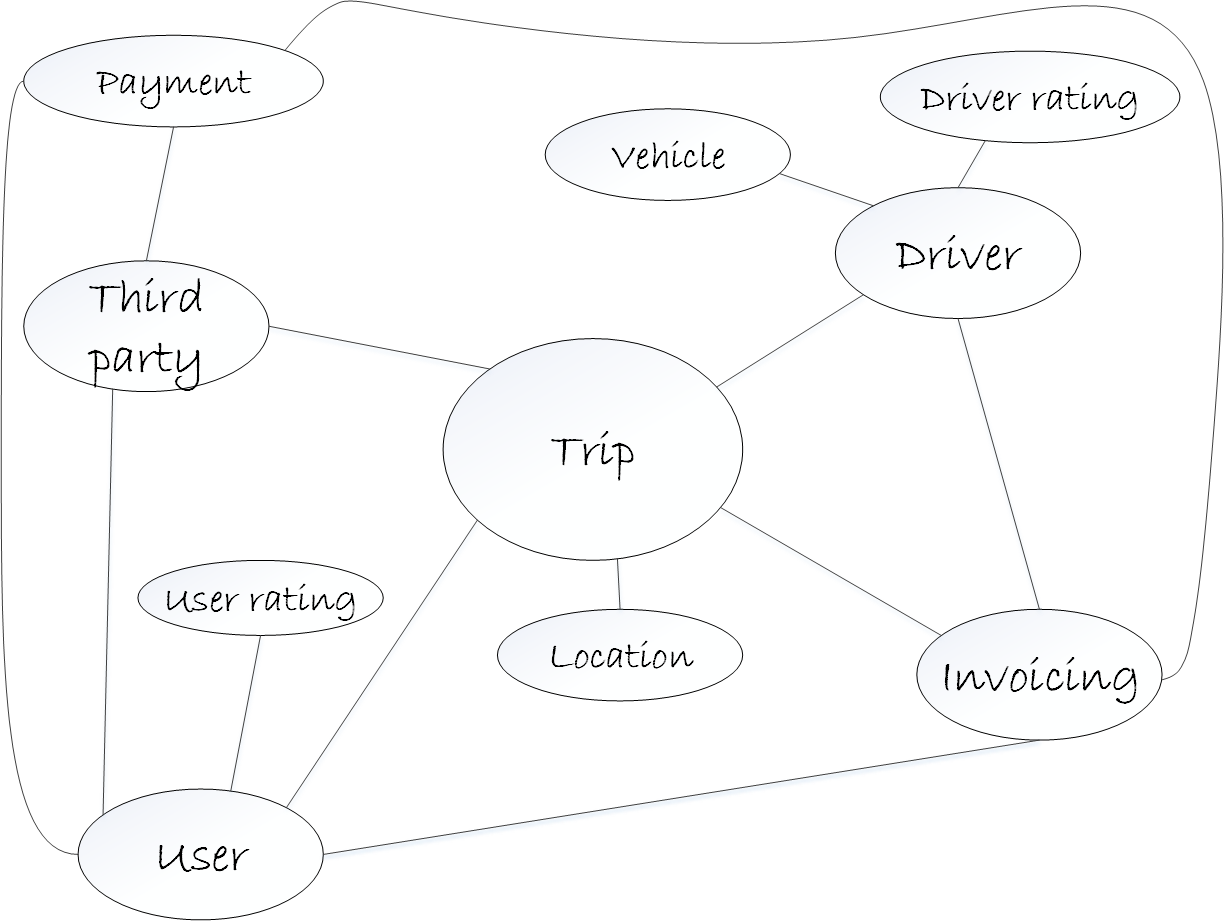
After that analysis you can notice that there are five main components and how is the relation between them:
- Trip: is the heart of the system, that’s why is placed in the center of the diagram.
- Driver: It’s part of the system core because enables the Trip functionality.
- User: It’s part of the system core as well and manage all information related with the user.
- Invoicing: takes care of pricing and coordinates the payment.
- Payment: it’s an external system which makes the payment itself.
Bounded Contexts
This diagram represents the boundaries within the domain, how they are related to each other and identifies easily the subsystems into the whole domain, which ones could be a microservices in our system since a bounded context marks the boundary of a particular domain model and as we already know a microservice only has one particular responsibility, so the functionality in a microservice should not span more than one bounded context. If you find that a microservice mixes different domain models together, that’s a sign that there is something wrong with your domain analysis and you may need to go back and refine it.
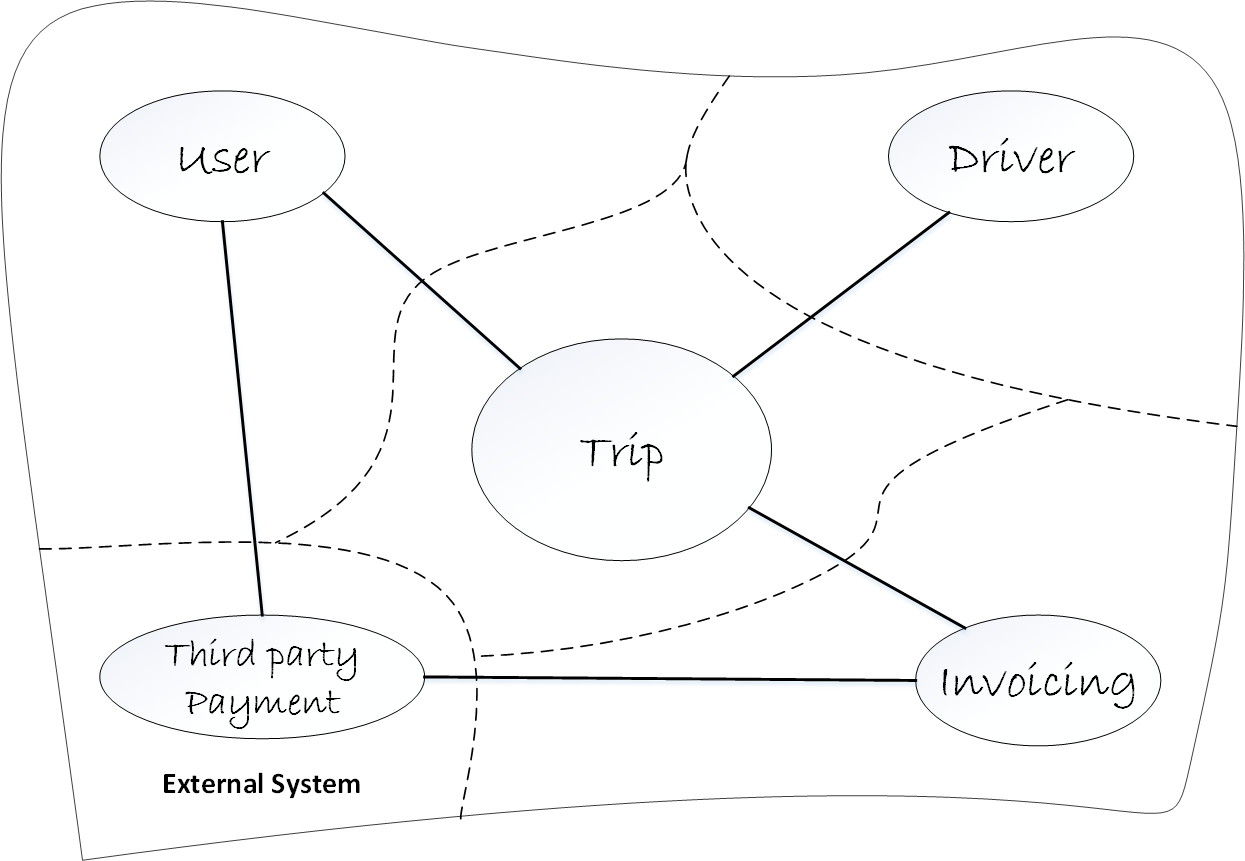
As you can see there are five bounded contexts (one external system between them), so, they are candidates to be microservices, but not necessarily every bounded context has to be it, it depends on the problem and your needs, so in this case and based on the problem proposed earlier, we’re going to choose Trip and Invoicing bounded contexts so they will be our microservices for this problem, since as you already know, the problem here is related with the scalability and availability around the trips.
Classes model
This is a very simple abstraction just to model this problem in a very basic but useful way, in order to apply DDD in our solution, that’s why you will see things like aggregates, entities and value objects in the next diagram. Notice that there is nothing about the external system, but it doesn’t mean that you should not worry about to model it, in this case, is just for the example propose, but to deal with that, we’re going to use a pattern that Eric Evans called Anti-corruption layer.
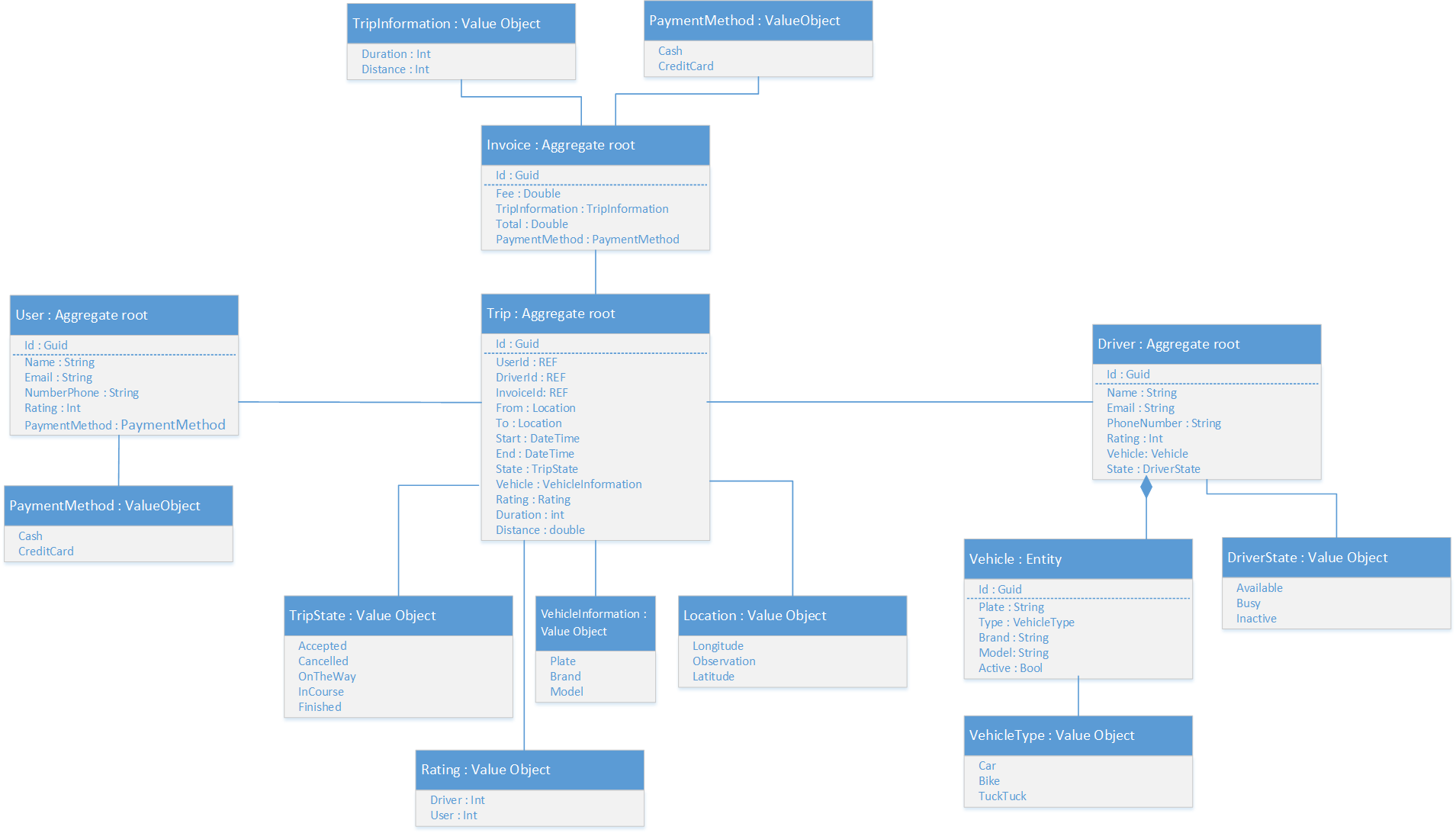
At this point we have spent a lot of time understanding the problem and designing the solution, that’s good and we always need to spend enough time in this phase. Usually at this point we haven’t made any decisions about implementation or technologies (beyond what I have told you about Docker and Azure Service Fabric), so in the next post we’re going to propose the architecture and we’re going to make some decisions about technologies and implementation, so stay tune because the next posts going to be really interesting!